
星空体育科技:十大必知的人工智能算法
随着人工智能技术(ai)的不断普及,各种算法在推动这一领域的发展中扮演着重要角色。从用于预测房价的线性回归算法到支持自动驾驶汽车的神经网络,这些算法默默地为无数应用提供支持和运转。随着数据量的增加和计算能力的提升,人工智能算法的性能和效率也在不断星空智能科技提升。这些算法的应用范围越来越广泛,涵盖了医疗诊断、金融风险评估、自然语言处理等
今天,我们将带您一览这些热门的人工智能算法(线性回归、逻辑回归、决策树、朴素贝叶斯、支持向量机(SVM)、集成学习、K近邻算法、K-means算法、神经网络、强化学习Deep Q-Networks ),探索它们的工作原理、应用场景以及在现实世界中的影响力。

示例代码(使用Python的Scikit-learn库构建一个简单的线性回归模型):
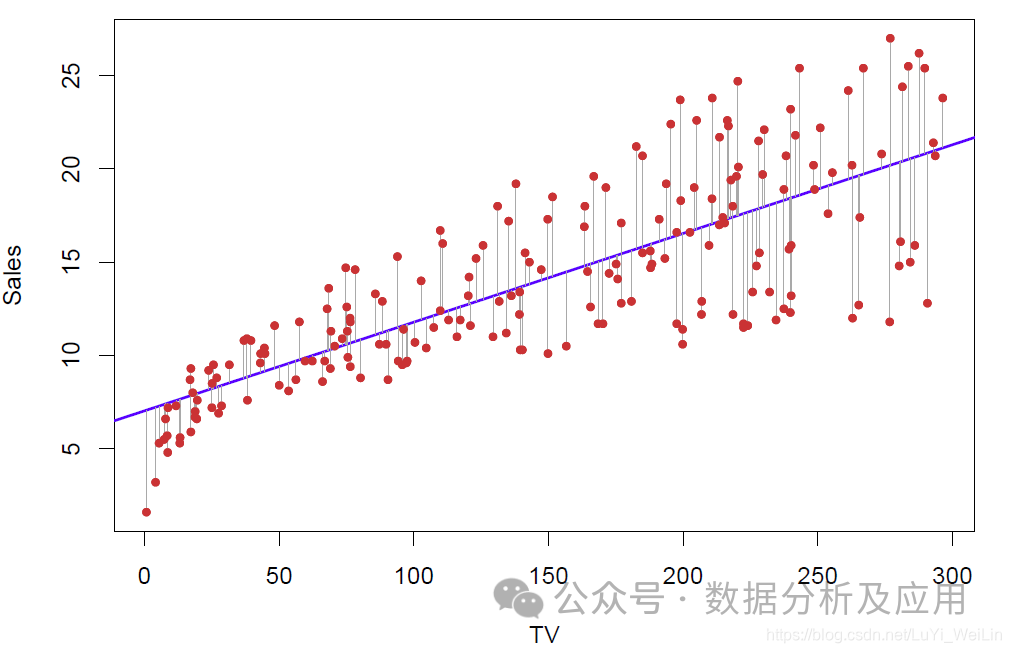
from sklearn.linear_model import LinearRegressionfrom sklearn.datasets import make_regression# 生成模拟数据集X, y = make_regression(n_samples=100, n_features=1, noise=0.1)# 创建线性回归模型对象lr = LinearRegression()# 训练模型lr.fit(X, y)# 进行预测predictions = lr.predict(X)
示例代码(使用Python的Scikit-learn库构建一个简单的逻辑回归模型):
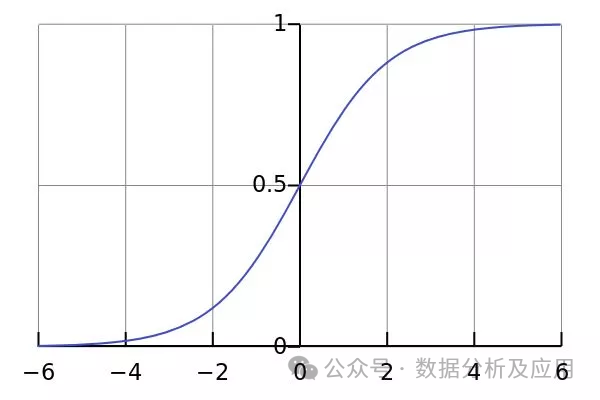
from sklearn.linear_model import LogisticRegressionfrom sklearn.datasets import make_classification# 生成模拟数据集X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)# 创建逻辑回归模型对象lr = LogisticRegression()# 训练模型lr.fit(X, y)# 进行预测predictions = lr.predict(X)
示例代码(使用Python的Scikit-learn库构建一个简单的决策树模型):
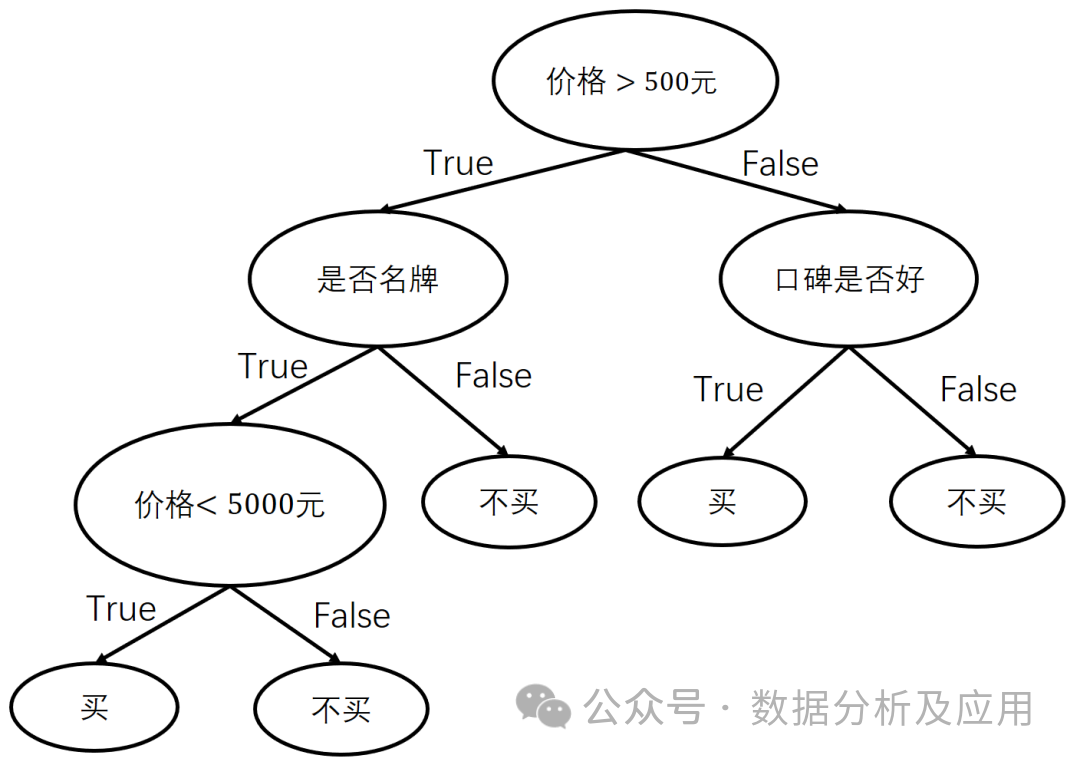
from sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树模型对象dt = DecisionTreeClassifier()# 训练模型dt.fit(X_train, y_train)# 进行预测predictions = dt.predict(X_test)
示例代码(使用Python的Scikit-learn库构建一个简单的朴素贝叶斯分类器):

from sklearn.naive_bayes import GaussianNBfrom sklearn.datasets import load_iris# 加载数据集iris = load_iris()X = iris.datay = iris.target# 创建朴素贝叶斯分类器对象gnb = GaussianNB()# 训练模型gnb.fit(X, y)# 进行预测predictions = gnb.predict(X)
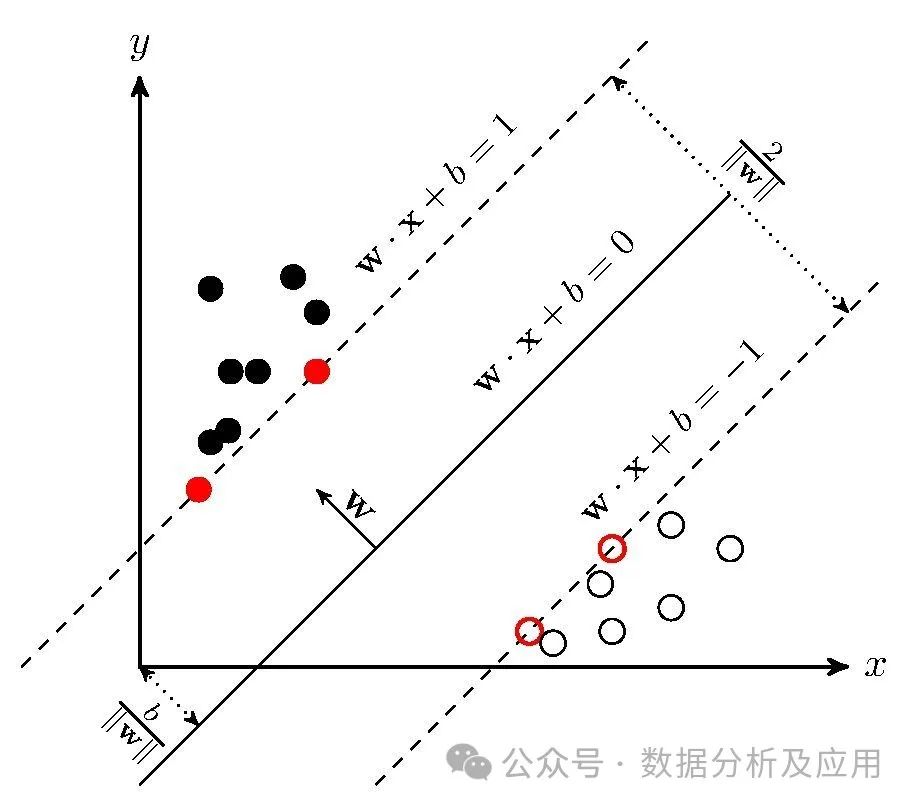
from sklearn import svmfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_stat星空智能科技e=42)# 创建SVM分类器对象,使用径向基核函数(RBF)clf = svm.SVC(kernel=rbf)# 训练模型clf.fit(X_train, y_train)# 进行预测predictions = clf.predict(X_test)
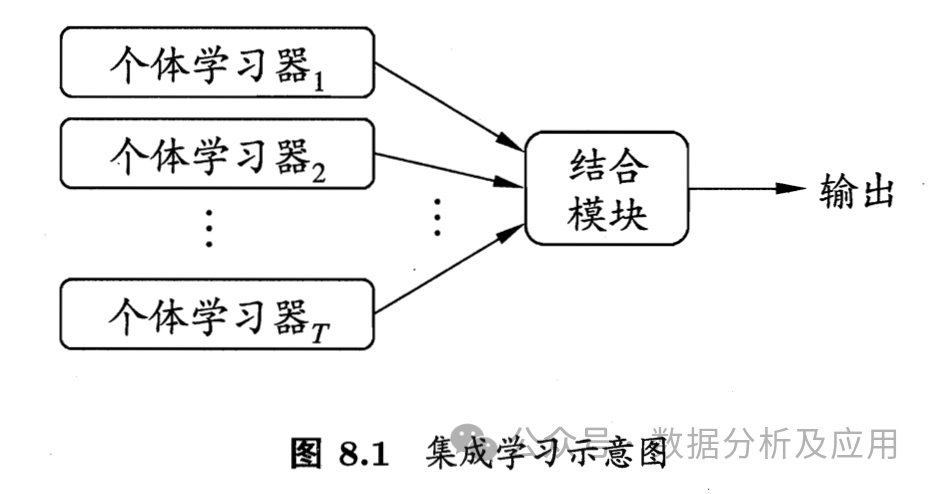
模型原理:集成学习是一种通过构建多个基本模型并将它们的预测结果组合起来以提高预测性能的方法。集成学习策略有投票法、平均法、堆叠法和梯度提升等。常见集成学习模型有XGBoost、随机森林、Adaboost等
模型训练:首先使用训练数据集训练多个基本模型,然后通过某种方式将它们的预测结果组合起来,形成最终的预测结果。
示例代码(使用Python的Scikit-learn库构建一个简单的投票集成分类器):
from sklearn.ensemble import VotingClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建基本模型对象和集成分类器对象lr = LogisticRegression()dt = DecisionTreeClassifier()vc = VotingClassifier(estimators=[(lr, lr), (dt, dt)], voting=hard)# 训练集成分类器vc.fit(X_train, y_train)# 进行预测predictions = vc.predict(X_test)
示例代码(使用Python的Scikit-learn库构建一个简单的K近邻分类器):
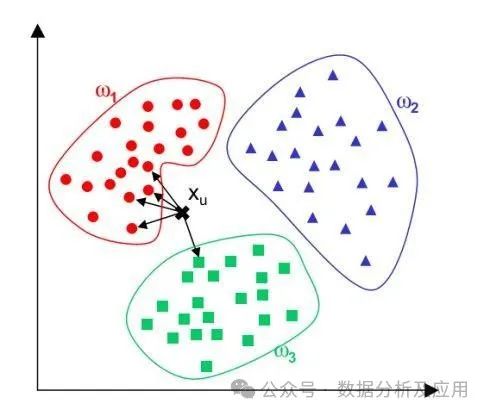
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建K近邻分类器对象,K=3knn = KNeighborsClassifier(n_neighbors=3)# 训练模型knn.fit(X_train, y_train)# 进行预测predictions = knn.predict(X_test)
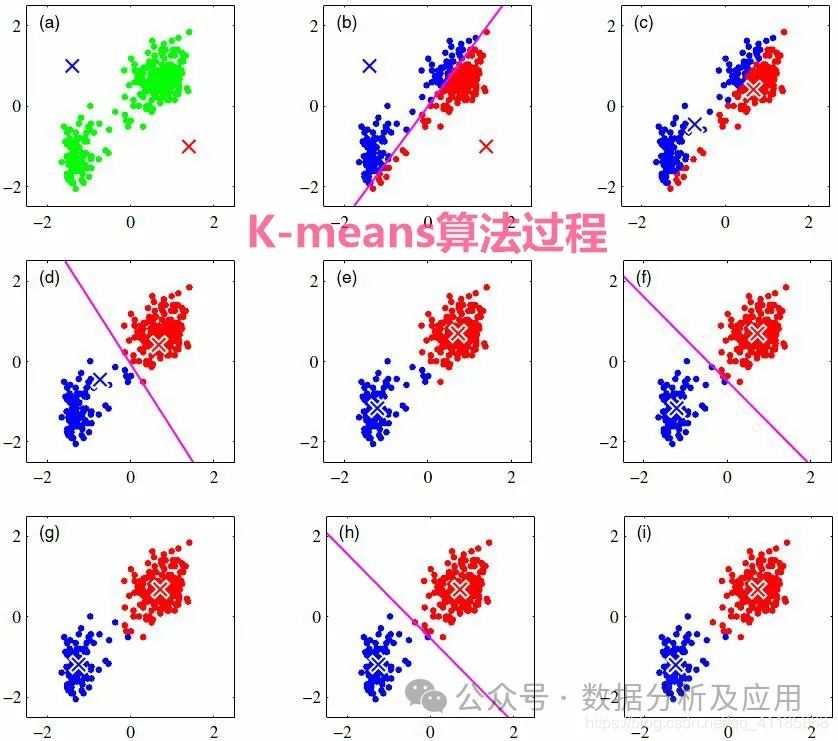
from sklearn.cluster import KMeansfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as plt# 生成模拟数据集X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)# 创建K-means聚类器对象,K=4kmeans = KMeans(n_clusters=4)# 训练模型kmeans.fit(X)# 进行预测并获取聚类标签labels = kmeans.predict(X)# 可视化结果plt.scatter(X[:, 0], X[:, 1], c=labels, cmap=viridis)plt.show()
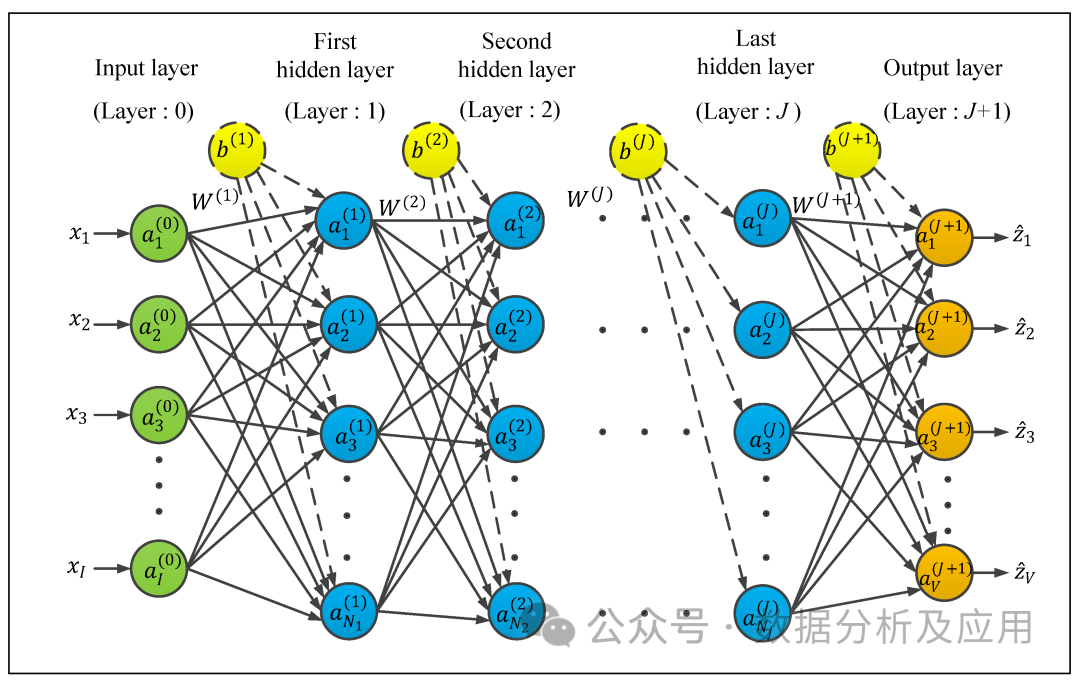
模型原理:神经网络是一种模拟人脑神经元结构的计算模型,通过模拟神经元的输入、输出和权重调整机制来实现复杂的模式识别和分类等功能。神经网络由多层神经元组成,输入层接收外界信号,经过各层神经元的处理后,最终输出层输出结果。
模型训练:神经网络的训练是通过反向传播算法实现的。在训练过程中,根据输出结果与实际结果的误差,逐层反向传播误差,并更新神经元的权重和偏置项,以减小误差。
优点:能够处理非线性问题,具有强大的模式识别能力,能够从大量数据中学习复杂的模式。
缺点:容易陷入局部最优解,过拟合问题严重,训练时间长,需要大量的数据和计算资源。
示例代码(使用Python的TensorFlow库构建一个简单的神经网络分类器):
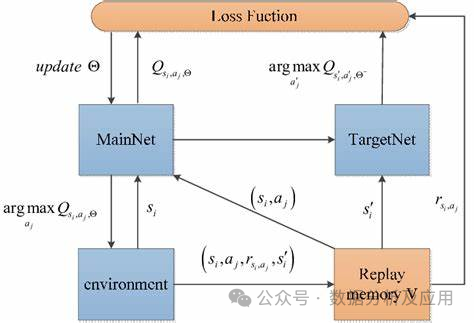
模型原理:Deep Q-Networks (DQN) 是一种结合了深度学习与Q-learning的强化学习算法。它的核心思想是使用神经网络来逼近Q函数,即状态-动作值函数,从而为智能体在给定状态下选择最优的动作提供依据。
模型训练:DQN的训练过程包括两个阶段:离线阶段和在线阶段。在离线阶段,智能体通过与环境的交互收集数据并训练神经网络。在线阶段,智能体使用神经网络进行动作选择和更新。为了解决过度估计问题,DQN引入了目标网络的概念,通过使目标网络在一段时间内保持稳定来提高稳定性。
优点:能够处理高维度的状态和动作空间,适用于连续动作空间的问题,具有较好的稳定性和泛化能力。
示例代码(使用Python的TensorFlow库构建一个简单的DQN强化学习模型):
ory = deque(maxlen=2000)self.gamma = 0.85self.epsilon = 1.0self.epsilon_min = 0.01self.epsilon_decay = 0.995self.learning_rate = 0.005self.model = self.create_model()self.target_model = self.create_model()self.target_model.set_weights(self.model.get_weights())def create_model(self):model = Sequential()model.add(Flatten(input_shape=(self.state_size,)))model.add(Dense(24, activation=relu))model.add(Dense(24, activation=relu))model.add(Dense(self.action_size, activation=linear))return modeldef remember(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def act(self, state):if len(self.memory) 1000:self.epsilon *= self.epsilon_decayif self.epsilon
每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。







